menu
Mustafa的小窝
search
brightness_6
search
搜索一下
bubble_chart
搜索
label_outline
标签云
#996
(1)
Mustafa的小窝
store
主页
book
分类
keyboard_arrow_down
人工智能
0
LLMS大模型
4
短视频
1
强者思维
2
人工智能
2
数据库
1
向量数据库
1
inbox
文章归档
check_box_outline_blank
关于
2. 从HuggingFace下载千问模型、数据、微调并运行
mustafa3264 · 2025-03-08 · 237浏览 · LLMS大模型
color_lens
切换字体
·
A-
18
A+
视频链接 [3. 从HuggingFace下载千问模型、数据、微调并运行(上)_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1f5NmeiECN/ "3. 从HuggingFace下载千问模型、数据、微调并运行(上)_哔哩哔哩_bilibili") [3. 从HuggingFace下载千问模型、数据、微调并运行(下)_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1E5NmeqEyb/ "3. 从HuggingFace下载千问模型、数据、微调并运行(下)_哔哩哔哩_bilibili") # 安装docker # 安装NVIDIA Container Toolkit 安装该工具主要是为了docker可以挂载Nvidia GPU设备。 ## 在线安装 ### 对于ubuntu系统 ```shell sudo apt install curl -y curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list sudo apt-get update sudo apt-get install -y nvidia-container-toolkit ``` ### 对于Centos系统 ```shell sudo yum install curl -y curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo sudo yum install -y nvidia-container-toolkit ``` ## 离线安装 ### 对于Ubuntu系统 下载以下安装包: ```shell # 分别打开如下链接 https://github.com/NVIDIA/libnvidia-container/blob/gh-pages/stable/ubuntu18.04/amd64/libnvidia-container1_1.9.0-1_amd64.deb https://github.com/NVIDIA/libnvidia-container/blob/gh-pages/stable/ubuntu18.04/amd64/libnvidia-container-tools_1.9.0-1_amd64.deb https://github.com/NVIDIA/libnvidia-container/blob/gh-pages/stable/ubuntu18.04/amd64/nvidia-container-toolkit_1.9.0-1_amd64.deb https://github.com/NVIDIA/libnvidia-container/blob/gh-pages/stable/ubuntu18.04/amd64/nvidia-docker2_2.10.0-1_all.deb ``` 点击下载 下载好的安装包执行如下命令即可安装: ```shell dpkg -i libnvidia-container1_1.9.0-1_amd64.deb dpkg -i libnvidia-container-tools_1.9.0-1_amd64.deb dpkg -i nvidia-container-toolkit_1.9.0-1_amd64.deb dpkg -i nvidia-docker2_2.10.0-1_all.deb ``` 安装完成后需要重启docker以生效 `systemctl restart docker` ### 对于Centos系统 参考ubuntu的方式寻找适合自己系统的rpm包进行安装 这里假设是Centos7,则在如下页面寻找[libnvidia-container/stable/centos7/x86_64 at gh-pages · NVIDIA/libnvidia-container · GitHub](https://github.com/NVIDIA/libnvidia-container/tree/gh-pages/stable/centos7/x86_64) ``` https://github.com/NVIDIA/libnvidia-container/blob/gh-pages/stable/centos7/x86_64/libnvidia-container-devel-1.9.0-1.x86_64.rpm https://github.com/NVIDIA/libnvidia-container/blob/gh-pages/stable/centos7/x86_64/libnvidia-container-tools-1.9.0-1.x86_64.rpm https://github.com/NVIDIA/libnvidia-container/blob/gh-pages/stable/centos7/x86_64/nvidia-container-toolkit-1.9.0-1.x86_64.rpm https://github.com/NVIDIA/libnvidia-container/blob/gh-pages/stable/centos7/x86_64/nvidia-docker2-2.10.0-1.noarch.rpm ``` 下载好后安装命令为 ```shell rpm -ivh libnvidia-container-devel-1.9.0-1.x86_64.rpm rpm -ivh libnvidia-container-tools-1.9.0-1.x86_64.rpm rpm -ivh nvidia-container-toolkit-1.9.0-1.x86_64.rpm rpm -ivh nvidia-docker2-2.10.0-1.noarch.rpm ``` 安装完成后需要重启docker以生效`systemctl restart docker` # 镜像制作 ## 下载镜像 这里在Nvidia NGC上下载一个比较干净的镜像,模型开发需要的pip包我们自己来装「比如xtuner」。 镜像仓库:dockerhub 对于NVIDIA的GPU,很多基础的镜像名字(编译安装好各类软件包的环境)可以在NGC上找到,网址为:[Data Science, Machine Learning, AI, HPC Containers | NVIDIA NGC](https://catalog.ngc.nvidia.com/containers?filters=&orderBy=weightPopularDESC&query=&page=&pageSize=) 下载什么版本镜像来匹配自己的cuda版本呢?可以通过执行nvidia-smi来查看,我这台服务器是cuda 12.4,如下图所示,那我们最好也是下载cuda12.x对应的docker镜像(不需要严格对齐版本)。 找到对应的镜像名字: 这里选择的cuda版本和机器安装的cuda版本一致,都是12.x;此外选择一个自己常用的操作系统版本,比如这里我选择的是ubuntu22.04,值得一提的是,这里的系统版本和自己机器上的系统版本没有必然联系,机器上只要可以运行docker即可。 执行下载镜像的命令,这个过程的耗时和各自的网络速度有关: ```shell # 刚刚复制的镜像名字放在docker pull后面即可 docker pull nvcr.io/nvidia/pytorch:23.10-py3 ``` ## 启动镜像 启动镜像时有一些参数如下。执行如下命令后,就已经启动了镜像并进入了容器内部,接下来执行的所有命令都是在容器内部进行的。 ```shell # --gpus=all 表示将机器上的所有GPU挂载到容器内 # -v /data2/:/datasets表示将本地的/data2 目录挂载到容器的/datasets目录 docker run -it --gpus=all -v /data2/:/datasets nvcr.io/nvidia/pytorch:23.10-py3 bash ``` ## 开始安装环境 现在在容器内,开始执行环境安装命令: ```shell apt-get update apt-get install libaio-dev -y pip install xtuner[all]==0.1.18 -i https://mirrors.ustc.edu.cn/pypi/web/simple pip3 install "fschat[model_worker,webui]" -i https://mirrors.ustc.edu.cn/pypi/web/simple pip3 install jupyterlab -i https://mirrors.ustc.edu.cn/pypi/web/simple pip install opencv-python==4.8.0.74 -i https://mirrors.ustc.edu.cn/pypi/web/simple pip uninstall transformer_engine flash-attn pip install datasets==2.18.0 ``` 安装过程如下「这个过程大约持续10~20分钟,主要看机器的网速」: 保存镜像 将制作好镜像进行保存,上面的容器内部截图中显示了一个id,使用这个容器id即可保存安装好的环境。 ```shell #xtuner-fastchat-cuda122:23.10-py3表示给镜像取一个新的名字「命名形式为xxx:yyy」 docker commit dd129233d4f5 xtuner-fastchat-cuda122:23.10-py3 ``` # 运行微调测试 ## 启动环境 ```shell # 用新的镜像启动容器 # 参数--shm-size 32G表示容器运行环境添加了32G的共享内存 # 参数-p 8888:8888表示将容器内部的8888端口和主机上的8888端口进行映射 docker run -it --shm-size 32G --gpus=all --network=host -v /mnt/nfs_share/data2/:/code/ -v /mnt/nfs_share/data2/:/dataset xtuner-fastchat-cuda122:23.10-py3 bash# 进入容器后执行如下命令开启jupyter-lab cd /code jupyter-lab --allow-root --ip='*' --NotebookApp.token='' --NotebookApp.password='' & ``` 在自己的浏览器中新建一个页面,输入http://127.0.0.1:8888/lab即可进入jupyterlab界面 ## 运行测试 我们还是以微调qwen0.5B作为例子,展示下代码无缝迁移: step1: 模型下载 ```shell export HF_ENDPOINT=https://hf-mirror.com huggingface-cli download Qwen/Qwen1.5-0.5B-Chat --resume-download --local-dir-use-symlinks False --local-dir /dataset/Qwen1.5-0.5B-Chat ``` 数据下载 ```shell export HF_ENDPOINT=https://hf-mirror.com huggingface-cli download tatsu-lab/alpaca --repo-type dataset --revision main --local-dir-use-symlinks False --local-dir /dataset/datasets/tatsu-lab___alpaca/data/ ``` 算法文件(qwen1_5_0_5b_chat_full_alpaca_e3.py) ```python # Copyright (c) OpenMMLab. All rights reserved. from datasets import load_dataset from mmengine.dataset import DefaultSampler from mmengine.hooks import (CheckpointHook, DistSamplerSeedHook, IterTimerHook, LoggerHook, ParamSchedulerHook) from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR, LinearLR from torch.optim import AdamW from transformers import AutoModelForCausalLM, AutoTokenizer from xtuner.dataset import process_hf_dataset from xtuner.dataset.collate_fns import default_collate_fn from xtuner.dataset.map_fns import alpaca_map_fn, template_map_fn_factory from xtuner.engine.hooks import (DatasetInfoHook, EvaluateChatHook, VarlenAttnArgsToMessageHubHook) from xtuner.engine.runner import TrainLoop from xtuner.model import SupervisedFinetune from xtuner.parallel.sequence import SequenceParallelSampler from xtuner.utils import PROMPT_TEMPLATE, SYSTEM_TEMPLATE ####################################################################### # PART 1 Settings # ####################################################################### # Model pretrained_model_name_or_path = '/dataset/Qwen1.5-0.5B-Chat/' use_varlen_attn = False # Data alpaca_en_path = '/dataset/datasets/tatsu-lab___alpaca/data/' prompt_template = PROMPT_TEMPLATE.qwen_chat max_length = 2048 pack_to_max_length = False # parallel sequence_parallel_size = 1 # Scheduler & Optimizer batch_size = 1 # per_device accumulative_counts = 16 accumulative_counts *= sequence_parallel_size dataloader_num_workers = 0 max_epochs = 3 optim_type = AdamW lr = 2e-5 betas = (0.9, 0.999) weight_decay = 0 max_norm = 1 # grad clip warmup_ratio = 0.03 # Save save_steps = 500 save_total_limit = 2 # Maximum checkpoints to keep (-1 means unlimited) # Evaluate the generation performance during the training evaluation_freq = 500 SYSTEM = SYSTEM_TEMPLATE.alpaca evaluation_inputs = [ '请给我介绍五个上海的景点', 'Please tell me five scenic spots in Shanghai' ] ####################################################################### # PART 2 Model & Tokenizer # ####################################################################### tokenizer = dict( type=AutoTokenizer.from_pretrained, pretrained_model_name_or_path=pretrained_model_name_or_path, trust_remote_code=True, padding_side='right') model = dict( type=SupervisedFinetune, use_varlen_attn=use_varlen_attn, llm=dict( type=AutoModelForCausalLM.from_pretrained, pretrained_model_name_or_path=pretrained_model_name_or_path, trust_remote_code=True)) ####################################################################### # PART 3 Dataset & Dataloader # ####################################################################### alpaca_en = dict( type=process_hf_dataset, dataset=dict(type=load_dataset, path=alpaca_en_path), tokenizer=tokenizer, max_length=max_length, dataset_map_fn=alpaca_map_fn, template_map_fn=dict( type=template_map_fn_factory, template=prompt_template), remove_unused_columns=True, shuffle_before_pack=True, pack_to_max_length=pack_to_max_length, use_varlen_attn=use_varlen_attn) sampler = SequenceParallelSampler \ if sequence_parallel_size > 1 else DefaultSampler train_dataloader = dict( batch_size=batch_size, num_workers=dataloader_num_workers, dataset=alpaca_en, sampler=dict(type=sampler, shuffle=True), collate_fn=dict(type=default_collate_fn, use_varlen_attn=use_varlen_attn)) ####################################################################### # PART 4 Scheduler & Optimizer # ####################################################################### # optimizer optim_wrapper = dict( type=AmpOptimWrapper, optimizer=dict( type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay), clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False), accumulative_counts=accumulative_counts, loss_scale='dynamic', dtype='float16') # learning policy # More information: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md # noqa: E501 param_scheduler = [ dict( type=LinearLR, start_factor=1e-5, by_epoch=True, begin=0, end=warmup_ratio * max_epochs, convert_to_iter_based=True), dict( type=CosineAnnealingLR, eta_min=0.0, by_epoch=True, begin=warmup_ratio * max_epochs, end=max_epochs, convert_to_iter_based=True) ] # train, val, test setting train_cfg = dict(type=TrainLoop, max_epochs=max_epochs) ####################################################################### # PART 5 Runtime # ####################################################################### # Log the dialogue periodically during the training process, optional custom_hooks = [ dict(type=DatasetInfoHook, tokenizer=tokenizer), # dict( # type=EvaluateChatHook, # tokenizer=tokenizer, # every_n_iters=evaluation_freq, # evaluation_inputs=evaluation_inputs, # system=SYSTEM, # prompt_template=prompt_template) ] if use_varlen_attn: custom_hooks += [dict(type=VarlenAttnArgsToMessageHubHook)] # configure default hooks default_hooks = dict( # record the time of every iteration. timer=dict(type=IterTimerHook), # print log every 10 iterations. logger=dict(type=LoggerHook, log_metric_by_epoch=False, interval=1), # enable the parameter scheduler. param_scheduler=dict(type=ParamSchedulerHook), # save checkpoint per `save_steps`. checkpoint=dict( type=CheckpointHook, by_epoch=False, interval=save_steps, max_keep_ckpts=save_total_limit), # set sampler seed in distributed evrionment. sampler_seed=dict(type=DistSamplerSeedHook), ) # configure environment env_cfg = dict( # whether to enable cudnn benchmark cudnn_benchmark=False, # set multi process parameters mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0), # set distributed parameters dist_cfg=dict(backend='nccl'), ) # set visualizer visualizer = None # set log level log_level = 'INFO' # load from which checkpoint load_from = None # whether to resume training from the loaded checkpoint resume = False # Defaults to use random seed and disable `deterministic` randomness = dict(seed=None, deterministic=False) # set log processor log_processor = dict(by_epoch=False) ``` 算法上传到自己本地启动的notebook中: 开始微调 ```shell mkdir -p /userhome/xtuner-workdir NPROC_PER_NODE=1 xtuner train qwen1_5_0_5b_chat_full_alpaca_e3_copy.py --work-dir /userhome/xtuner-workdir --deepspeed deepspeed_zero3_offload ``` 如果显存不够可以考虑使用lora或者qlora 3090的显存24G,全量参数微调不够用,需要开启lora训练 # 运行模型部署 打开4个终端,分别按顺序执行如下命令 ```shell python -m fastchat.serve.controller --host 0.0.0.0 python -m fastchat.serve.model_worker --model-path /dataset/Qwen1.5-0.5B-Chat/ --host 0.0.0.0 --num-gpus 1 --max-gpu-memory 20GiB python -m fastchat.serve.openai_api_server --host 0.0.0.0 curl http://localhost:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen1.5-0.5B-Chat", "prompt": "Once upon a time", "max_tokens": 41, "temperature": 0.5 }' ``` 调用结果返回正常: [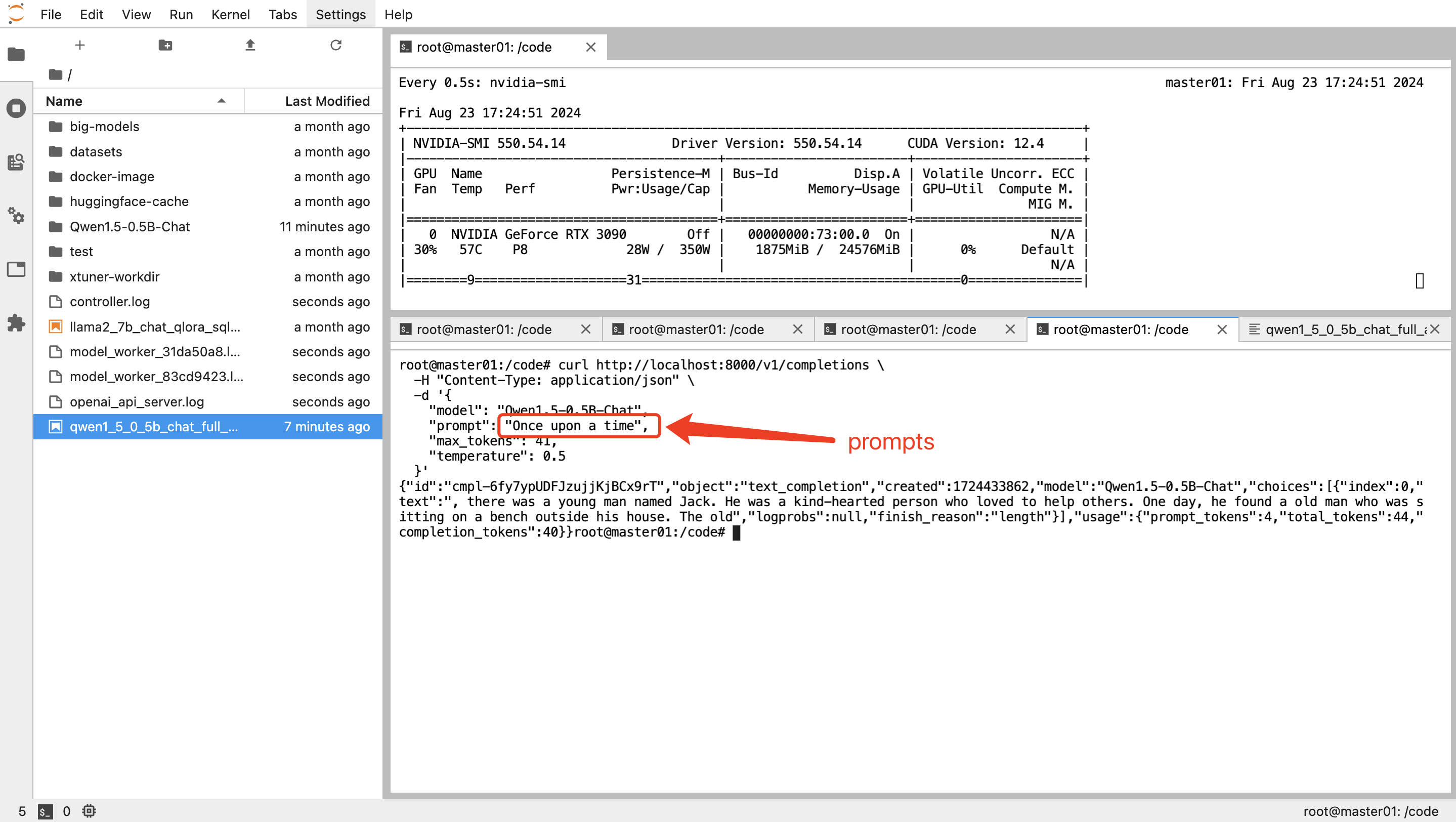](http://cdn.fanghailiang.cn/aa345db0d8d755c8179d5971d84b5eb1.png)
文章最后更新时间为:2025年03月08日 11时
本文章版权声明:
禁止转载
comment
评论区
取消回复
添加新评论
OωO表情
©2026 bilibili.com
textsms
内容不能为空
account_circle
昵称不能为空
email
邮件地址格式错误
web
beach_access
验证码不能为空
keyboard
发表评论
star_outline
咱快来抢个沙发吧!
©2026 Mustafa的小窝
Theme
Romanticism2.1
by
Akashi
Powered by
Typecho

comment 评论区
star_outline 咱快来抢个沙发吧!